灵感库导读
从 Word、PPT、Excel、PDF 到字幕文件,真正节省时间的是翻译后不用重新排版、公式不丢、文本框不乱、结果能直接交付。
很多人第一次用 AI 翻译文件时,预期其实很简单:上传一个 Word、PPT 或 PDF,等它翻完,然后直接发给客户或同事。
但真正做过几次以后就会发现,最麻烦的经常不是“这句话翻得准不准”,而是翻完以后文件还能不能交付。
举几个很常见的场景:
- Word 里表格翻完以后列宽被撑开
- PPT 文本框被译文挤爆,标题和正文重叠
- Excel 单元格样式还在,但内容换行完全乱了
- PDF 可以抽出文字,却很难写回接近原来的结构
- 字幕翻译准确,但时间轴和分行读起来很别扭
这类问题说明一件事:文件翻译不是单句翻译问题,而是文件工程问题。
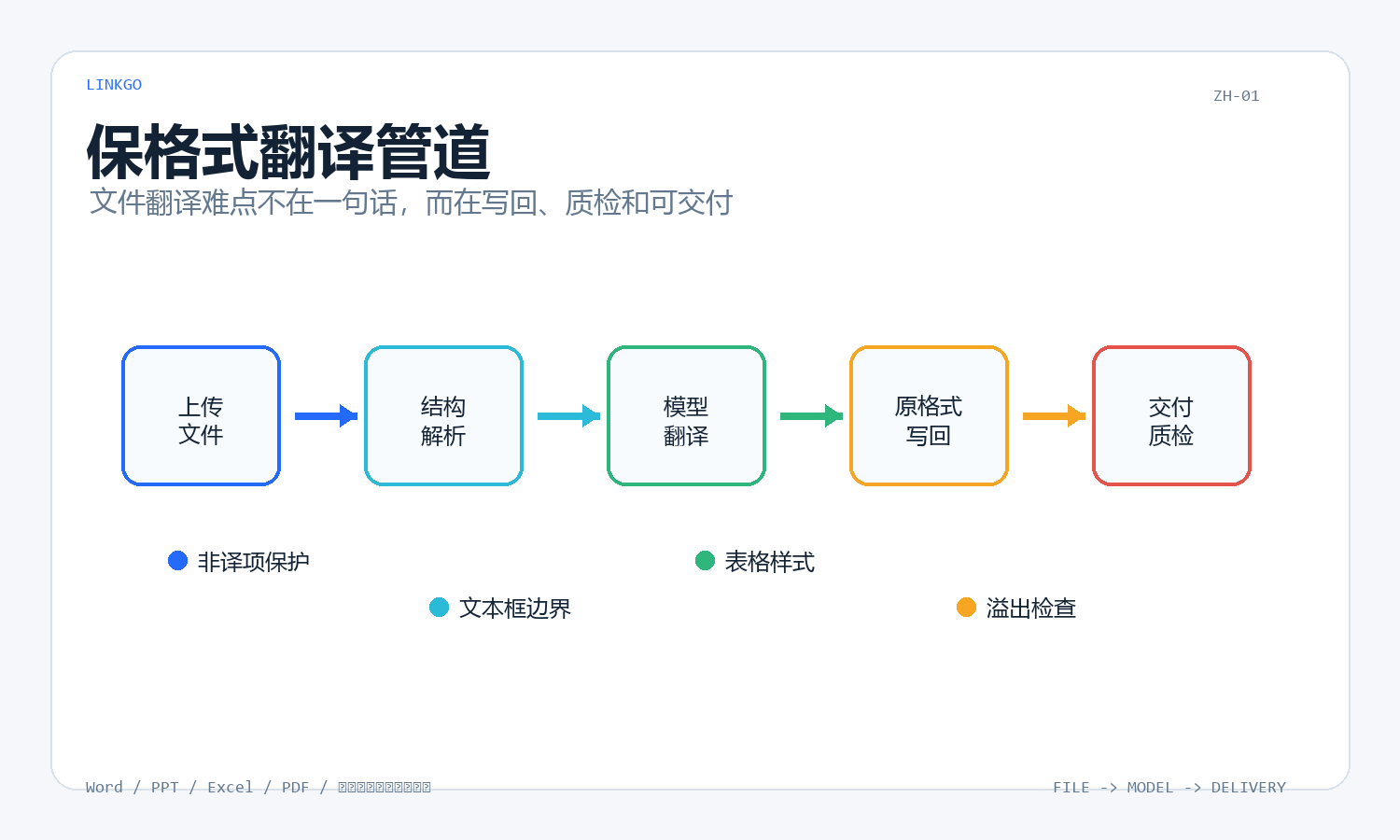
一个真实可用的文件翻译流程,至少要分成几层:
- 先识别文件结构,而不是直接抽纯文本
- 把可翻译内容、数字、公式、代码、链接、专名分开处理
- 译文写回原结构时保留样式、层级和位置关系
- 写回后检查溢出、漏译、未译短句和格式异常
- 让用户拿到可下载、可继续修改的结果文件
我做 LinkGo 时,越来越觉得“保格式”不是一个锦上添花的功能,而是文件翻译能不能落地的分界线。
如果工具只给你一段译文文本,后面所有排版、复制、校对、重命名、归档都还要人来补。AI 节省的时间,很可能又被人工返工吃掉。
所以我现在判断一个 AI 翻译工具,会先看它能不能完成这几个动作:
- 能不能处理真实 Office 文件,而不是只处理纯文本
- 能不能尽量保留原来的样式和结构
- 能不能识别表格、文本框、页眉页脚、脚注、字幕这些复杂区域
- 能不能在交付前做质量检查
LinkGo 现在主推的方向,就是把“上传 -> 解析 -> 翻译 -> 写回 -> 质检 -> 下载”做成一条连续链路。模型能力当然重要,但真正决定用户体验的,是最后拿到的文件能不能直接进入下一步工作。
如果你经常翻译 Word、PPT、PDF、字幕或批量资料,建议不要只看翻译速度,也要看它能不能减少后续返工。
因为很多时候,AI 翻译真正省下来的时间,不在翻译那一秒,而在你不用重新排版的那半小时。
适合继续了解
如果你关注文件翻译、智能体自动执行、本地部署或团队多语言交付,可以在 LinkGo 灵感库继续查看相关专题。