翻译完成不等于可以交付。LinkClaw 可以沿着上一次结果继续审校漏译、数字、术语、语气和格式风险。
很多文件翻译任务,真正的问题不是“能不能生成译文”,而是“生成以后敢不敢交付”。
尤其是合同、技术手册、产品资料、工程文档、医学材料、跨境电商内容和字幕文件,翻完以后通常还要问几件事:
- 有没有漏译?
- 数字、日期、型号、单位有没有被改坏?
- 同一个术语前后是否一致?
- 译文是不是太机翻腔?
- 原文格式有没有被破坏?
这就是 LinkClaw 适合接在 LinkEngine 后面的原因。
LinkEngine 负责翻译,LinkClaw 负责追问和续作
LinkEngine 更像主翻译工作台。
它负责把文件解析、分片、翻译、检查、写回,尽量稳定地产出 DOCX、PPTX、XLSX、PDF、SRT、EPUB、DXF 等结果。
但用户拿到译文后,经常会继续说:
帮我看看这次翻译质量怎么样。 有没有漏译和术语不一致? 把刚才那批文件整理成一个交付清单。 这份译文客户说有问题,帮我重点查一下。
这些请求不再是单纯“翻译文件”,而是围绕上一次任务继续分析、审校、排障和整理。
这时候 LinkClaw 就有价值了。
它能把最近交付的源文件、译文、结构化 JSON、任务状态、语言方向、模型和资源上下文带给 OpenClaw 或 Hermes Agent,让智能体沿着上一次结果继续工作。
为什么不能只做规则快检?
规则检查很重要,但它不等于翻译质量审校。
规则可以发现:
- 某个分片没有译文。
- 目标语言里还残留源语言。
- 数字或保护 token 漂移。
- 占位符、URL、公式、标签被改坏。
但规则很难判断:
- 这句话有没有错译。
- 术语在这个语境里是否合适。
- 译文是否自然。
- 专业表达是否像目标行业的人会写。
所以 LinkClaw 的深度审校会先做规则预检,再让 OpenClaw / Hermes 做语义判断。
这不是为了多跑模型,而是为了把“机器可检查的风险”和“语言理解层面的风险”分开处理。
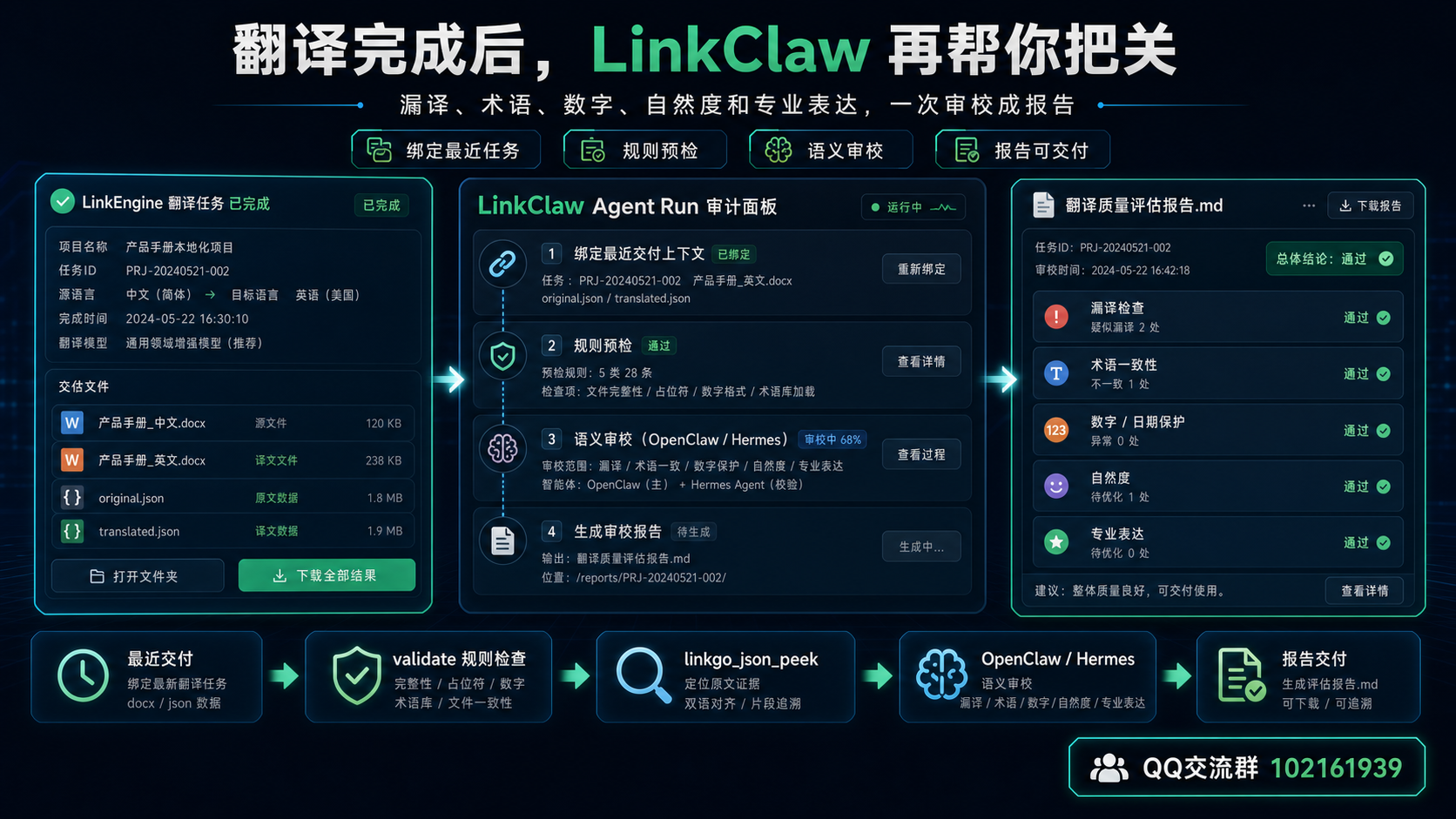
一个典型审校流程
用户可以直接在聊天页说:
检查刚才那份译文质量。
LinkClaw 会尽量绑定最近一次交付上下文,而不是让用户重新上传一堆文件。
理想流程是:
- 找到最近翻译任务。
- 绑定原文 JSON 和译文 JSON。
- 跑 validate,先看漏译、残留、数字和保护项。
- 用
linkgo_json_peek按问题 ID 查看上下文,避免一次读完整大 JSON。 - 让 OpenClaw / Hermes 判断错译、漏译、术语一致性、自然度和专业表达。
- 生成
翻译质量评估报告.md。 - 前端只展示审校结论和报告文件,内部 trace 留在折叠控制台。
这个流程有一个关键点:智能体不是重新猜文件内容,而是沿着 LinkEngine 的结构化结果继续审校。
为什么这对团队很有用?
翻译项目最怕“交付前最后一公里”没人兜底。
机器翻译很快,但项目负责人还是要担心:
- 有没有一两处漏掉?
- 有没有某个专名翻错?
- 有没有因为格式保护导致某段没有处理?
- 有没有客户最在意的术语漂移?
LinkClaw 的价值,是把这些担心变成一份可读报告。
报告里应该说清楚:
- 发现了哪些风险。
- 风险来自规则检查还是语义审校。
- 对应原文和译文是什么。
- 建议怎么修改。
- 哪些地方已经通过。
这比简单告诉用户“质量良好”更有用。
OpenClaw 和 Hermes 分别适合什么?
在 LinkClaw 里,用户可以选择 OpenClaw 或 Hermes。
OpenClaw 更适合偏工具化、Gateway、工作区执行、结构化输出和可折叠工具轨迹的场景。
Hermes 更适合偏多轮会话、技能协同、持续上下文和复杂推理的场景。
但无论选哪个,LinkClaw 都会尽量保持同一条产品链路:
- 文件来自 LinkEngine。
- 模型跟随主项目配置。
- 术语库、翻译记忆和领域画像继续注入。
- 结果回到 LinkGo 前端。
- 内部日志保留,交付文件突出展示。
用户不需要为了换智能体而换整个工作方式。
最后
文件翻译不是生成译文就结束。
真正让人放心的交付,通常还需要审校、解释、复查、修复和归档。
LinkEngine 负责把文件翻出来。
LinkClaw 负责让智能体沿着结果继续检查、追问和补救。
这两者配合起来,才更像一个面向真实文件交付的 AI 工作台。
如果你也在关注 AI 文件翻译、翻译质量审校和本地智能体工作流,
如果你关注文件翻译、智能体自动执行、本地部署或团队多语言交付,可以在 LinkGo 灵感库继续查看相关专题。